
Abstract
Faults are the primary culprits of breaking the high availability of cloud systems, even leading to costly outages. As the scale and complexity of clouds increase, it becomes extraordinarily difficult to understand, detect and diagnose faults. During outages, engineers record the detailed information of the whole life cycle of faults (i.e., fault occurrence, fault detection, fault identification, and fault mitigation) in the form of post-mortems. In this paper, we conduct a quantitative and qualitative study on 354 public post-mortems collected in three popular large-scale clouds, 97.7% of which spans from 2015 to 2021. By reviewing and analyzing post-mortems, we go through the life cycle of faults in clouds and obtain 10 major findings. Based on these findings, we further reach a series of actionable guidelines for better fault handling.
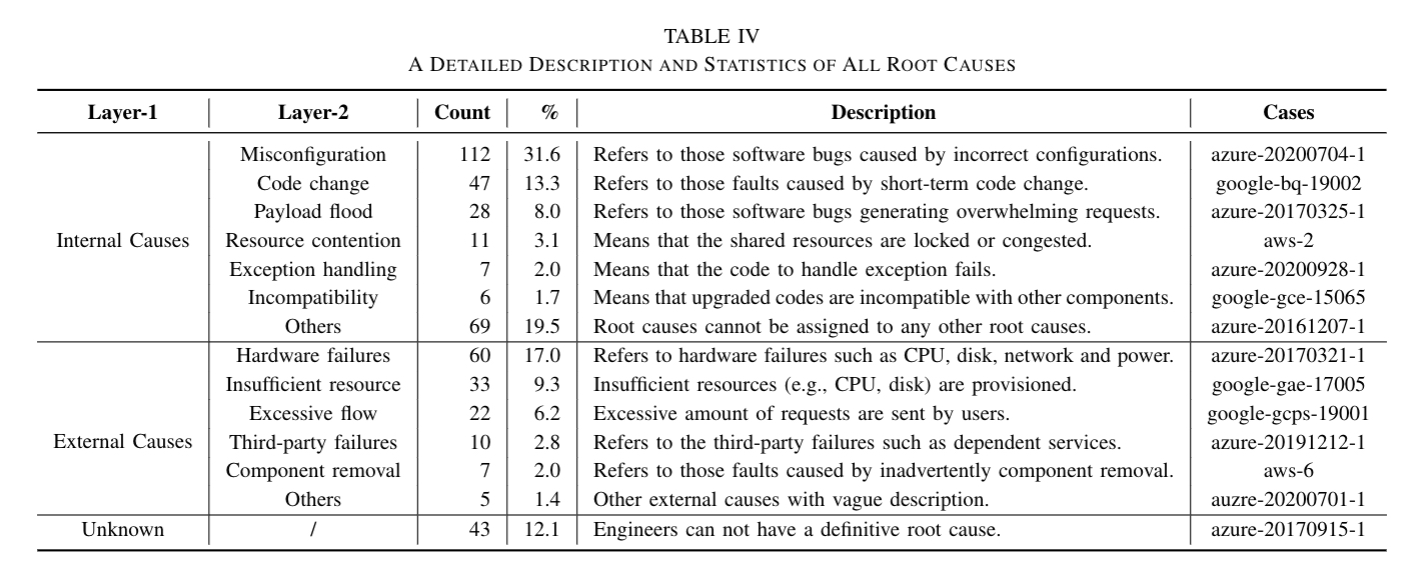
The blow figure shows the fault type of cloud incident.
Guangba Yu
Postdoc Focus on Reliablity of Distributed Systems
My research interests include cloud computing, microservices, AIOps, MLOps