
Abstract
With the ever increasing scale and complexity of online systems, incidents are gradually becoming commonplace. Without appropriate handling, they can seriously harm the system availability. However, in large-scale online systems, these incidents are usually drowning in a slew of issues (i.e., something abnormal, while not necessarily an incident), rendering them difficult to handle. Typically, these issues will result in a cascading effect across the system, and a proper management of the incidents depends heavily on a thorough analysis of this effect. Therefore, in this paper, we propose a method to automatically analyze the cascading effect of availability issues in online systems and extract the corresponding graph based issue representations incorporating both of the issue symptoms and affected service attributes. With the extracted representations, we train and utilize a graph neural networks based model to perform incident detection. Then, for the detected incident, we leverage the PageRank algorithm with a flexible transition matrix design to locate its root cause. We evaluate our approach using real-world data collected from the WeChat ® online service system, the largest instant message system in China. The results confirm the effectiveness of our approach. Moreover, our approach is successfully deployed in the company and eases the burden of operators in the face of a flood of issues and related alert signals.
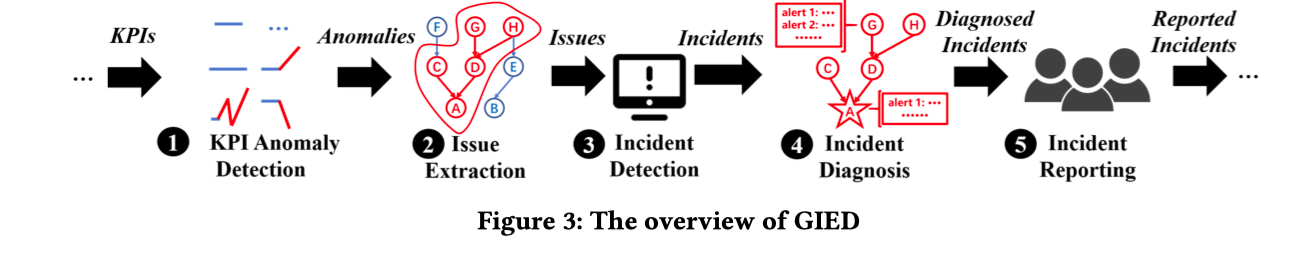
The blow figure shows the framework of GIED.
Guangba Yu
Postdoc Focus on Reliablity of Distributed Systems
My research interests include cloud computing, microservices, AIOps, MLOps